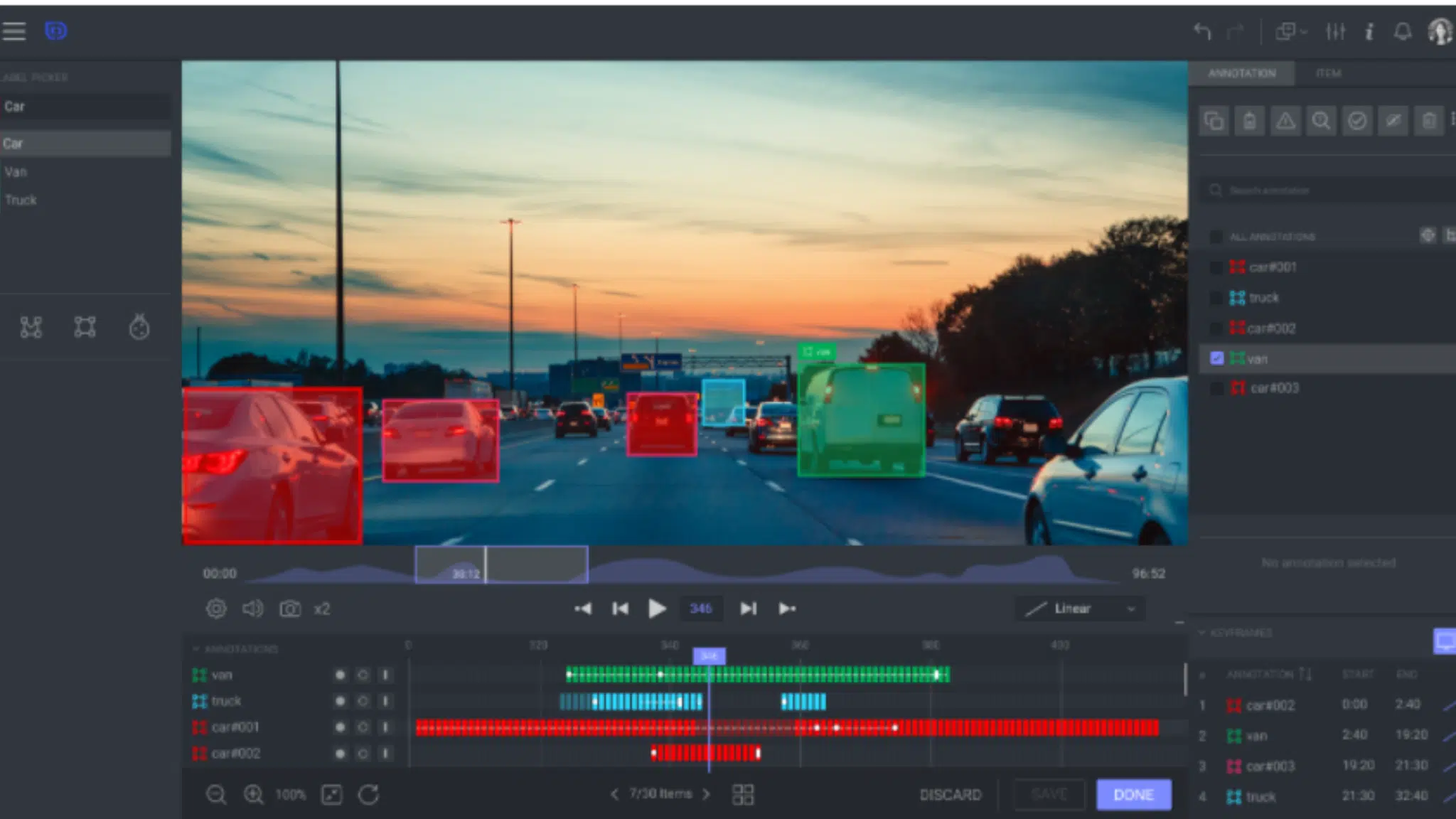
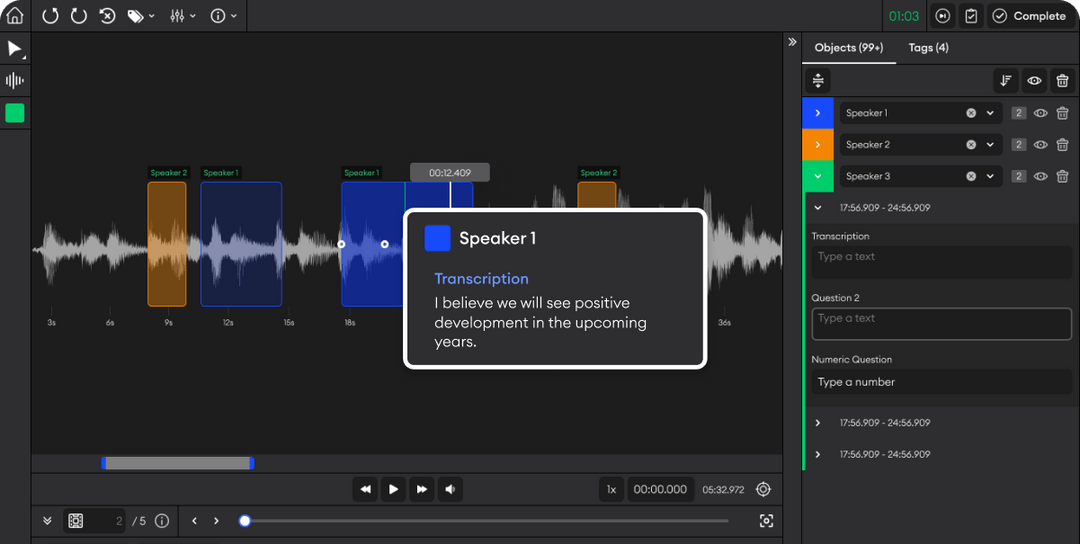
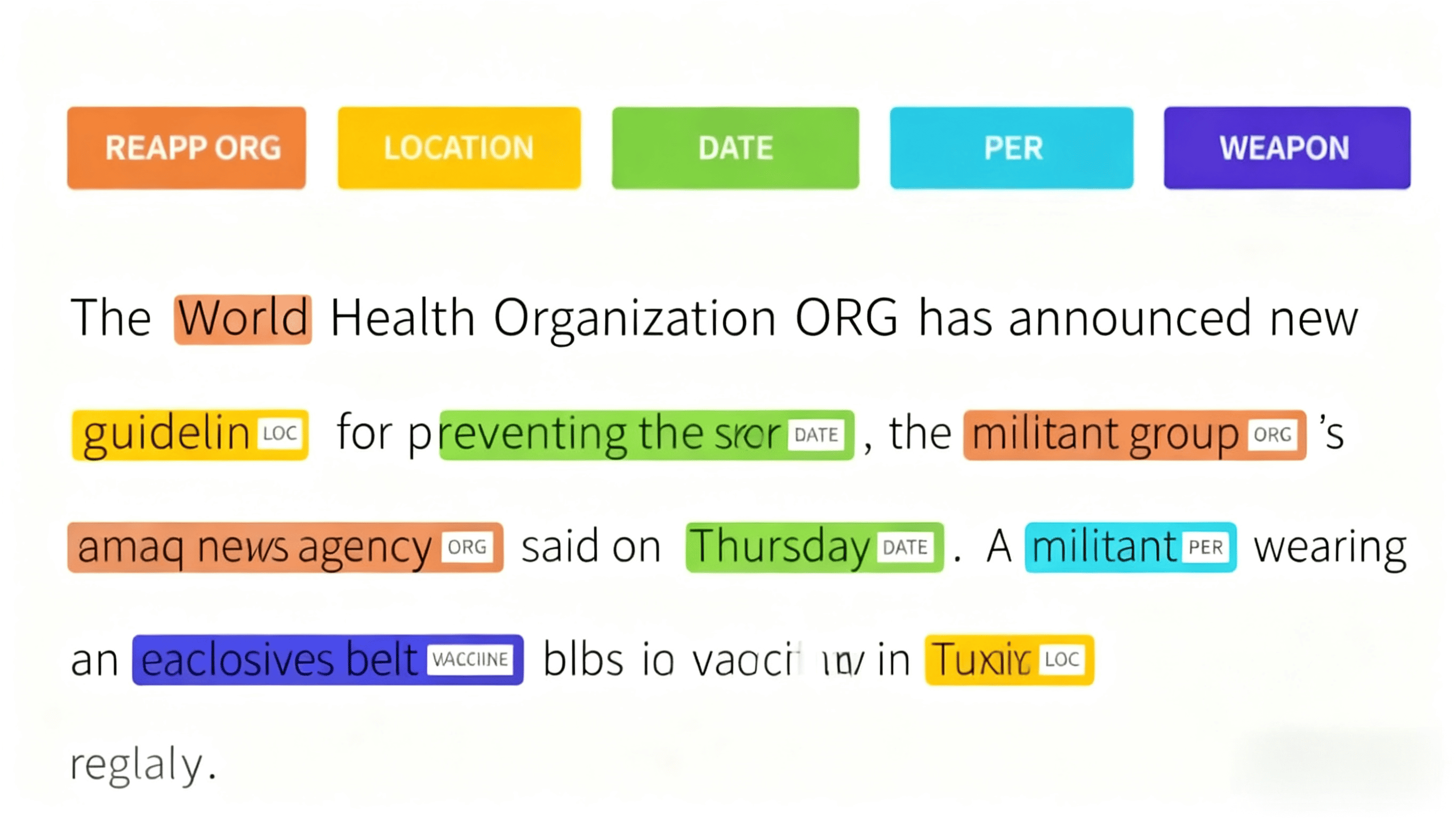
Train your model to understand the diversity of natural language, capturing the nuance of dialect and speaker demographics through highly accurate audio annotation. Audio annotation includes transcription and timestamping of speech data and can be applied to varied use cases – such as staging aggressive speech indicators and non-speech sounds like glass breaking for security and emergency applications.
Key capabilities include:
Speech Transcription: Convert spoken language in varied recording environments (e.g. multi-speaker, background noise) into text for analysis and model training.
Language and Dialect Identification: Annotate audio data to recognize different languages and dialects.
Speech Labelling: Label audio data with speaker information such as demographics, speech topic or emotion to enhance personalized AI applications.